- Info@SaminRay.Com
- 88866172 021
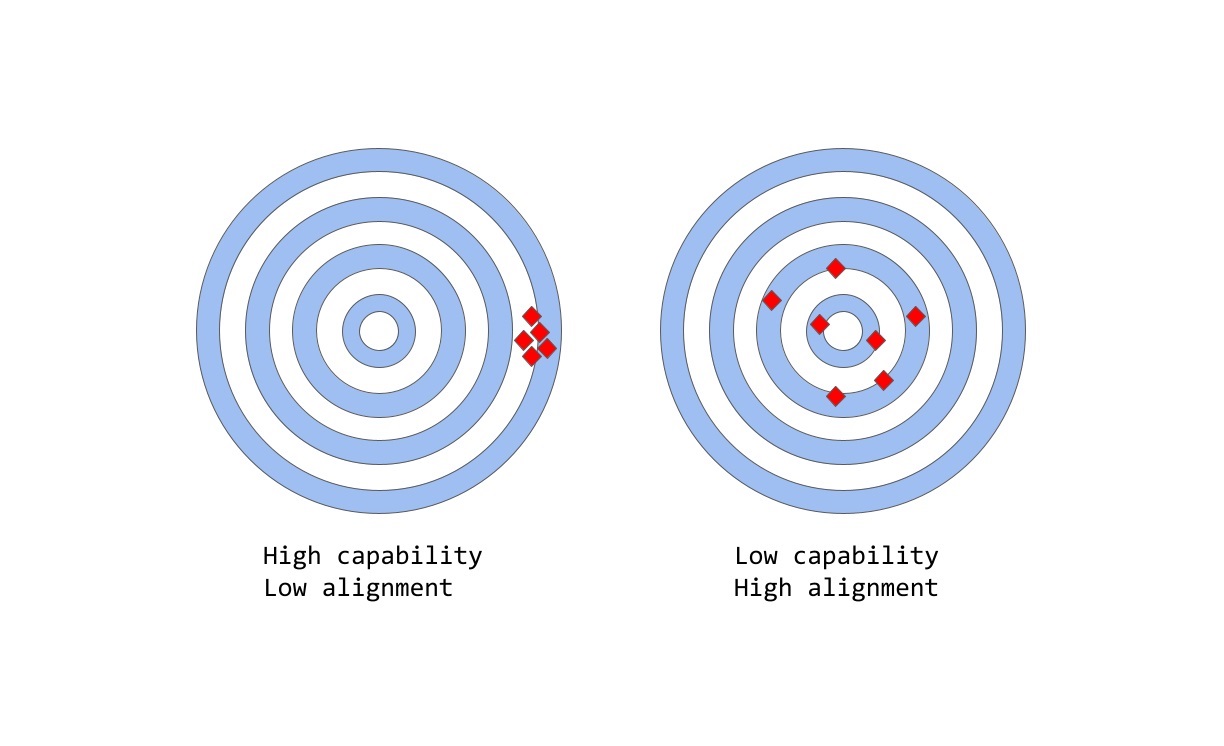
چالش Capability/Alignment در مدلهای NLP
چالش Capability/Alignment به تعبیری دیگر مانند چالش Accuracy/Precision است.
چالش Capability/Alignment به تعبیری دیگر مانند چالش Accuracy/Precision است.
در زمینه یادگیری ماشین، اصطلاح capability به توانایی یک مدل برای انجام یک کار خاص یا مجموعهای از وظایف اشاره دارد. capability یک مدل معمولاً با میزان توانایی آن برای بهینهسازی تابع هزینه خود (عبارت ریاضی که هدف مدل را مشخص میکند) ارزیابی میشود. برای مثال، مدلی که برای پیشبینی قیمتهای بازار سهام طراحی شده است، ممکن است تابع هزینهای داشته باشد که دقت پیشبینیهای مدل را اندازهگیری میکند. اگر مدل قادر به پیشبینی دقیق حرکت قیمت سهام در طول زمان باشد، توانایی بالایی برای آن مدل در نظر گرفته میشود.
از سوی دیگر alignment به آنچه که ما واقعاً میخواهیم مدل انجام دهد در مقابل آنچه که برای انجام آن آموزش داده میشود مربوط میشود و سعی در پاسخ به این پرسش دارد که آیا تابع هزینه با مقاصد ما سازگار است؟ بهعبارتدیگر به میزان همسویی اهداف و رفتار یک مدل باارزشها و انتظارات انسانی اشاره دارد. بهعنوان یک مثال عینی ساده، فرض کنید که ما یک مدل Classifier پرنده بادقت بالا میخواهیم آموزش دهیم تا پرندگان را بهعنوان «گنجشک» یا «رابین» طبقهبندی کند و برای این کار از log loss که تفاوت بین توزیع احتمال پیشبینیشده توسط مدل و توزیع واقعی را اندازهگیری میکند بهعنوان تابع هزینه استفاده میکنیم. پس از اتمام فرایند آموزش، مدل ممکن است log loss کمی داشته باشد در چنین شرایطی capability مدلبالا است؛ اما با عملکرد ضعیف در طبق بندی داده test مشخص میگردد که دقت آن در مسئله طبقهبندی ضعیف است. در واقع، چنین میتوان گفت که log loss ارتباط درستی با موضوع دقت در مسئله طبقهبندی ندارد. این نمونهای از misalignment است که در آن مدل قادر به بهینهسازی هدف آموزشی است؛ اما باهدف نهایی آن مسئله همسو نیست.
مدلهای زبان جامع، مانند GPT-3، بر روی حجم وسیعی از دادههای متنی از اینترنت آموزشدیدهاند و میتوانند متنی شبیه به انسان تولید کنند، اما همیشه این احتمال وجود دارد که خروجیهایی تولید کنند که با انتظارات یا مقادیر مطلوب انسان سازگار نباشد. در واقع، تابع هدف آنها توزیع احتمال بر روی توالی کلمات است که به آنها امکان میدهد کلمه بعدی را در یک دنباله پیشبینی کنند.
باتوجهبه مطلب فوق چنین میتوان گفت که مدلهایی مانند GPT-3 مدلهایی misalignment شده هستند. بااینحال، در کاربردهای عملی، این مدلها برای انجام برخی امور ارزشمند هستند، پس باید چنین گفت که تفاوت آشکاری بین نحوه آموزش این مدلها و روشی که مایل به استفاده از آنها هستیم وجود دارد. ازنقطهنظر ریاضیاتی، یک ماشین که توزیع آماری توالیهای کلمات را محاسبه میکند میتواند انتخاب بسیار مؤثری باشد، اما ما انسانها زبان را از طریق انتخاب توالی کلمات متناسب با شرایط تولید میکنیم و در طی این فرایند بهصورت ضمنی نیز از دانش زمینهای و عقل سلیم خود نیز بهره میبریم. باتوجهبه این موضوع، طبیعتاً زمانی که مدلهای زبانی ماشینی مرسوم در برنامههایی استفاده شوند که به درجه بالایی از اعتماد یا قابلیت اطمینان نیاز دارند، مانند سیستمهای گفتگو یا دستیاران شخصی هوشمند، در جلب رضایت انسانها دچار مشکل میشوند. این امر ناشی از misalignment شدن آنمی باشد.
مشکل alignment در مدلهای زبانی جامع معمولاً بهصورت زیر ظاهر میشود:
- عدم کمک: عدم پیروی از دستورالعملهای صریح کاربر.
- توهمات: ساختن حقایق ساختگی یا اشتباه.
- عدم تفسیرپذیری: درک اینکه چگونه مدل به یک تصمیم یا پیشبینی خاص رسیده است برای انسان دشوار است.
- ایجاد خروجی مغرضانه یاسمی: یک مدل زبانی که بر روی دادههای جانبدارانه/سمی آموزشدیده است، ممکن است آن را در خروجی خود بازتولید کند.
اما این مشکل alignment به طور مشخص از کجا ناشی میشود؟ آیا این درست است که مدلهای زبانی به طور ذاتی در معرض misalignment قرار دارند؟ چگونه استراتژیهای آموزش مدل زبانی میتواند سبب ایجاد misalignment شوند؟
Next token prediction و Masked language modeling تکنیکهای اصلی مورداستفاده برای آموزش مدلهای زبانی مانند transformerها هستند. در رویکرد اول، به مدل دنبالهای از کلمات بهعنوان ورودی داده میشود و از آن خواسته میشود کلمه بعدی در دنباله را پیشبینی کند. بهعنوانمثال، اگر به مدل جمله "The cat sat on the" بهعنوان ورودی داده شود ممکن است "mat"، "chair" یا "floor" را بهعنوان کلمه بعدی پیشبینی کند، زیرا احتمال وقوع این کلمات باتوجهبه کلمات قبلی زیاد است. این مدل زبانی در واقع قادر است احتمال هر کلمه ممکن را باتوجهبه دنباله قبلی تخمین بزند.
رویکرد Masked languege modeling گونهای از Next token prediction است که در آن برخی از کلمات در جمله ورودی با یک نشانه خاص، مانند [MASK] جایگزین میشوند. سپس از مدل خواسته میشود تا کلمه صحیحی را که باید بهجای [MASK] درج شود را پیشبینی کند. بهعنوانمثال، اگر عبارت "The [MASK] sat on the" به مدل داده شود، ممکن است [MASK] را بهصورت "cat"، "dog" یا "rabbit" پیشبینی کند.
یکی از مزیتهای توابع هدف این تکنیکها این است که به مدل اجازه میدهد تا ساختار آماری زبان، مانند توالیهای رایج کلمات و الگوهای استفاده از کلمات را بیاموزد. این موضوع بهطورکلی به مدل کمک میکند تا متن طبیعی و روانتری تولید کند و این یک گام اساسی در مرحله پیش آموزش هر مدل زبانی است.
بااینحال، این توابع هدف همچنین میتوانند منجر به مشکلاتی نیز شوند، صرفاً به این دلیل که مدل قادر به تمایز بین یک خطای مهم و یک خطای بیاهمیت نیست. برای درک این موضوع مثال زیر را در نظر بگیرید، اگر به مدل جمله "The Roman Empire [MASK] with the reign of Augustus" بهعنوان ورودی داده شود آنگاه مدل ممکن است " began" یا "ended" را پیشبینی کند، زیرا هر دوکلمه احتمال وقوع بالایی دارند و همچنین هر دو جمله از نظر تاریخی نیز صحیح هستند، حتی اگر انتخاب دوم معنای بسیار متفاوتی را بیان کند.
بهطورکلی، این استراتژیهای آموزشی میتوانند منجر به misalignment مدل زبان برای برخی از وظایف پیچیدهتر شوند، زیرا مدلی که فقط برای پیشبینی کلمه بعدی در یک دنباله متن آموزشدادهشده است، ممکن است لزوماً مفاهیم سطح بالاتری از معنای آن را نیاموزد. در نتیجه بهاینترتیب تعمیمپذیری مدل برای وظایف یا زمینههایی که نیاز به درک عمیقتری از زبان دارند کاهش مییابد.
مرجع:
https://www.assemblyai.com/blog/how-chatgpt-actually-works/